Seata 分布式事务处理框架详解 构建可靠的数据处理服务
在微服务架构和分布式系统日益普及的今天,如何保证跨服务、跨数据库的数据一致性成为了一个核心挑战。分布式事务作为解决这一难题的关键技术,其实现框架的选择至关重要。阿里巴巴开源的 Seata 正是其中一款广受青睐的解决方案。本文将深入详解 Seata 框架,并探讨其如何赋能可靠的数据处理服务。
一、Seata 是什么?
Seata 是一款开源的分布式事务解决方案,其全称为 Simple Extensible Autonomous Transaction Architecture。它旨在以高性能和低侵入性的方式,为微服务架构提供简单易用的分布式事务服务。Seata 提供了 AT(自动补偿型)、TCC(Try-Confirm-Cancel)、SAGA 和 XA 四种事务模式,以适应不同的业务场景。
二、核心角色与工作原理
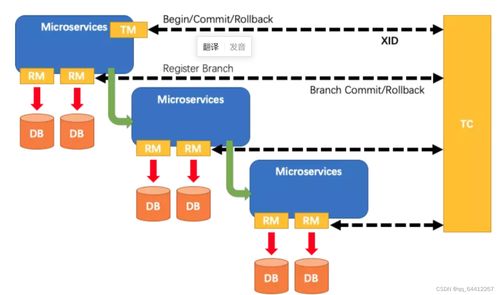
Seata 的架构包含三个核心角色:
- Transaction Coordinator (TC): 事务协调器。它是独立部署的服务器,负责维护全局事务的运行状态,协调并驱动全局事务的提交或回滚。这是 Seata 的大脑。
- Transaction Manager (TM): 事务管理器。它作为微服务中的一部分,负责定义全局事务的边界,开启、提交或回滚全局事务。通常由发起全局事务的业务服务担当。
- Resource Manager (RM): 资源管理器。它负责管理分支事务(即每个微服务本地的事务)相关的资源,向 TC 注册分支事务并报告其状态,并驱动分支事务的提交和回滚。每个参与分布式事务的微服务都是一个 RM。
其核心工作流程(以 AT 模式为例)可概括为:
- 第一阶段(执行与记录):TM 向 TC 发起全局事务。每个 RM 执行本地业务 SQL,并在提交前,由 Seata 的 JDBC 数据源代理自动生成“前置镜像”和“后置镜像”(即数据更新前后的快照),将此“undo_log”记录与本地事务一起提交到业务数据库。此时,本地事务已提交,但全局事务未完成。
- 第二阶段(异步提交/回滚):TM 根据所有分支事务的执行情况,向 TC 发起全局提交或回滚决议。
- 若决议为提交,TC 会异步通知所有 RM 删除对应的 undo_log 记录,流程快速完成。
- 若决议为回滚,TC 会根据之前记录的 undolog 中的“前置镜像”,生成反向补偿 SQL 发送给各 RM 执行,将数据还原,然后删除 undolog,从而实现数据的最终一致性。
三、四大事务模式详解
- AT 模式(默认且最常用):
- 特点:无侵入、高性能、对业务代码零改造。基于支持本地 ACID 事务的关系型数据库(如 MySQL、Oracle)。
- 原理:如上所述,通过拦截并解析 SQL,生成回滚日志,实现“一阶段提交,二阶段异步提交/补偿回滚”。
- 适用场景:绝大多数需要强一致性的普通微服务场景。
- TCC 模式:
- 特点:高性能、最终一致性、需要业务代码显式实现三个阶段接口。
- 原理:将业务逻辑拆分为 Try(尝试预留资源)、Confirm(确认执行业务)、Cancel(取消预留资源)三个操作,由 Seata 框架保证其最终协调一致。
- 适用场景:对性能要求高,且存在非事务型资源(如Redis、MQ)操作的场景,或需要自定义补偿逻辑的场景。
- SAGA 模式:
- 特点:长事务解决方案、业务侵入性高、最终一致性。
- 原理:将长流程事务拆分为一连串的本地事务,每个本地事务都有对应的补偿操作。流程正常执行时顺序执行,一旦某个节点失败,则逆向执行前面所有已成功节点的补偿操作。
- 适用场景:业务流程长、参与者包含遗留系统或无法提供事务资源(如第三方接口)的场景。
- XA 模式:
- 特点:强一致性、遵循 X/Open DTP 模型、资源锁定时间长。
- 原理:基于数据库本身的 XA 协议实现,TM 作为 AP,数据库作为 RM。执行阶段不提交,等待所有分支就绪后,由 TC 统一通知提交或回滚。
- 适用场景:需要强一致性,且业务执行时间短的场景。
四、在数据处理服务中的应用与最佳实践
数据处理服务往往涉及数据的抽取、转换、加载(ETL)、清洗、统计等多个步骤,且可能分散在不同的微服务中。Seata 能有效保障此类复杂数据流的一致性。
应用示例:一个订单支付成功后,需要依次调用“库存服务”扣减库存、“积分服务”增加积分、“通知服务”发送短信。这三个操作必须作为一个整体事务。使用 Seata AT 模式,只需在订单服务方法上添加 @GlobalTransactional 注解,即可保证三者同时成功或同时回滚。
最佳实践建议:
1. 模式选型:优先考虑 AT 模式,简单高效;涉及非数据库操作时,考虑 TCC;对于长时间运行的批处理任务,可评估 SAGA。
2. 服务设计:尽量将分布式事务的边界缩小,避免一个全局事务包含过多服务,以减少资源锁定时间和故障影响面。
3. 幂等性与防悬挂:在 TCC 或 SAGA 模式中,Confirm/Cancel 接口必须实现幂等性,以应对网络重试。同时要做好空回滚(Try未执行,Cancel已调用)和防悬挂(Cancel 比 Try 先执行)的防护。
4. TC 高可用:生产环境务必部署 TC 集群,并配置共享数据库(如 MySQL)或注册中心(如 Nacos、Eureka)以实现高可用。
5. 监控与日志:充分利用 Seata 的 Metrics 监控和详细的日志,便于排查事务失败问题。重点关注 undo_log 表的状态和大小。
五、
Seata 通过其清晰的角色划分、多样化的事务模式以及低侵入性的设计,为分布式系统,尤其是复杂的数据处理服务,提供了强大而灵活的事务一致性保障。理解其核心原理并根据具体业务场景选择合适的事务模式,是构建高可靠、高可用的数据驱动型应用的关键。随着云原生技术的发展,Seata 也在持续演进,与 Service Mesh 等新技术结合,未来必将在分布式事务领域扮演更重要的角色。
(本文首发于CSDN博客,旨在分享技术见解,欢迎交流讨论。)
如若转载,请注明出处:http://www.rikmuixpx.com/product/70.html
更新时间:2026-06-19 14:33:55