借助混沌工程工具ChaosBlade构建高可用分布式数据处理服务
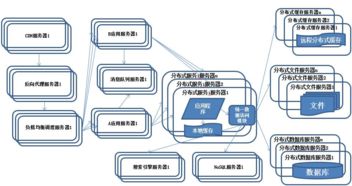
在当今以数据驱动的时代,分布式数据处理服务已成为企业核心基础设施的关键组成部分。这些服务需要处理海量数据,并保证7x24小时的持续可用性。复杂的分布式环境充满了不确定性,网络延迟、硬件故障、依赖服务中断等“混沌”事件时有发生。如何确保系统在面对这些不可避免的故障时依然坚如磐石?混沌工程为我们提供了答案,而ChaosBlade正是实践这一理念的利器。
一、 混沌工程:从被动应对到主动防御
混沌工程是一种通过在生产环境中故意引入故障,以验证系统在混乱条件下的韧性和可恢复性的学科。其核心思想是“未雨绸缪”,主动发现系统在设计和运维中隐藏的弱点,而不是等待真实故障发生后的被动救火。通过可控的实验,团队可以建立对系统行为的信心,并持续提升其高可用性。
二、 ChaosBlade:阿里开源的混沌实验利器
ChaosBlade是一款功能强大、场景覆盖全面的混沌实验工具。它由阿里巴巴开源并长期维护,具有以下核心优势:
- 场景丰富:支持从基础设施(CPU、内存、磁盘、网络)到应用层(JVM、HTTP、Dubbo、MySQL等)的广泛故障注入场景,完美契合分布式数据处理服务(如Flink、Spark、Kafka等)的测试需求。
- 简单易用:通过清晰的命令行工具或丰富的API,可以快速创建、管理和停止混沌实验,学习成本低。
- 精准可控:能够对实验的爆炸半径(影响范围)、持续时间和故障类型进行精细控制,确保实验安全。
- 开源开放:活跃的社区和良好的扩展性,允许用户根据自身业务特点定制故障场景。
三、 构建高可用数据处理服务的实践路径
借助ChaosBlade,我们可以系统化地构建和验证数据处理服务的高可用性,具体可分为四个阶段:
阶段一:定义稳态与假设
明确系统在正常情况下的“稳态”指标,例如数据处理延迟(P99)、吞吐量、成功率、积压队列长度等。然后,针对可能发生的故障(如Kafka Broker宕机、计算节点CPU满载、网络分区),提出“假设”,例如:“当某个TaskManager节点故障时,Flink作业应能在2分钟内自动恢复,且数据不丢失。”
阶段二:设计并执行混沌实验
使用ChaosBlade将上述假设转化为具体的实验。例如:
- 资源层实验:对运行Flink TaskManager的容器注入CPU满载(blade create cpu load)或内存占用故障,观察作业状态与资源调度。
- 中间件层实验:模拟Kafka Broker节点网络延迟(blade create network delay)或丢包,测试Spark Streaming作业的容错与反压机制。
- 应用层实验:模拟下游数据库(如MySQL)慢查询或连接失败,验证数据处理管道的降级与重试策略。
实验应从开发环境开始,逐步向预发和生产环境推进,并严格控制爆炸半径。
阶段三:观察与分析
在实验过程中,密切监控系统稳态指标和业务指标的变化。通过日志、链路追踪和监控仪表盘,深入分析系统行为:
- 故障是否被有效隔离?
- 自动恢复机制是否按预期触发?
- 是否有级联故障或雪崩效应?
- 告警系统是否及时响应?
阶段四:修复与固化
根据实验结果,识别系统中的脆弱点。这可能是缺少重试机制、熔断器配置不合理、资源配额不足,或是监控盲区。修复问题后,将成功的混沌实验固化为自动化测试用例,集成到CI/CD流水线中,形成常态化的韧性验证机制。
四、 关键注意事项
- 安全第一:始终在可控范围内进行实验,使用白名单、最小爆炸半径等策略,避免对生产业务造成实质性损害。
- 团队协作:混沌工程需要开发、测试、运维及SRE团队的共同参与,建立统一的故障认知和应急流程。
- 持续迭代:高可用建设不是一劳永逸的。随着系统架构演进和新功能引入,需要持续设计新的实验进行验证。
在分布式系统的复杂性面前,脆弱性始终存在。借助ChaosBlade实践混沌工程,使我们能够变被动为主动,将不确定性转化为提升系统韧性的驱动力。通过持续地“搞破坏”来验证和加固,我们最终能够构建出真正意义上高可用、可信赖的分布式数据处理服务,为业务的稳定运行保驾护航。从今天开始,不妨用一次小规模的ChaosBlade实验,迈出主动拥抱混沌、构建系统韧性的第一步。
如若转载,请注明出处:http://www.rikmuixpx.com/product/87.html
更新时间:2026-06-19 18:40:16